
Can you just imagine the magic of pushing one button and see your company’s new project materialize in a production environment? The software application code compiled and built, the data center infrastructure (heterogeneous and complex) set up, the application deployed and tested - ensuring compliance - and the business stakeholders given their beloved new campaign ready to use?
I’m working with colleagues and customers to better understand why there’s so much interest around DevOps, what are the business benefit and useful technology.
Here is that state of our reasoning, along with some notes that I collected in my research.
To make the matter easier for people that don’t have experience in managing the software release cycle, I imagined to take a triangle approach: analyse the business drivers that need to be addressed, what is a operational model that could provide the expected results and, finally, what is the enabling technology. With this top-down approach, understanding the concept gradually should be easier for IT professionals that are not expert in the field.

Business Drivers
In every company, Lines Of Business have a dream: have a new solution live in 1 month. It could be a marketing campaign, a new service for their customers, a process to produce new goods.
They think they just need smart developers and the availability of the required infrastructure, that given the spending on IT should not be an obstacle.
Unfortunately, sometimes they feel that IT is not efficient enough. It’s not a matter of technology, but of organization.
Some notes from https://puppetlabs.com/blog/why-every-cfo-should-advocate-devops (Bill Koefoed, the author, is the chief financial officer of Puppet Labs).
IT is the manufacturing of the 21st century. Let’s face it, most products and services these days depend on software, from social media to teleconferencing to household appliances that interact via the internet.
To get ahead of competitors, you have to get your new products and services out fast, test them for customer response, and quickly update to satisfy customer desires. Even as you’re increasing your rate of output, you have to reduce flaws, whether in delivery or the product itself.
That’s why DevOps is so important: The tools, practices and cultural orientation of DevOps enable greater efficiency in IT. Our 2014 State of DevOps report bears this out, both in terms of software throughput and business results. From the standpoint of throughput, we validated last year’s findings that high-performing IT teams (as defined by deployment frequency, lead time for changes and mean time to recover from failure) deploy up to 30 times more frequently than their lower-performing peers, with 50 percent fewer failures. This year, the most provocative finding was the strong connection we found between IT performance and financial performance. Companies with high-performing IT teams got better business results, as they were:
To get ahead of competitors, you have to get your new products and services out fast, test them for customer response, and quickly update to satisfy customer desires. Even as you’re increasing your rate of output, you have to reduce flaws, whether in delivery or the product itself.
That’s why DevOps is so important: The tools, practices and cultural orientation of DevOps enable greater efficiency in IT. Our 2014 State of DevOps report bears this out, both in terms of software throughput and business results. From the standpoint of throughput, we validated last year’s findings that high-performing IT teams (as defined by deployment frequency, lead time for changes and mean time to recover from failure) deploy up to 30 times more frequently than their lower-performing peers, with 50 percent fewer failures. This year, the most provocative finding was the strong connection we found between IT performance and financial performance. Companies with high-performing IT teams got better business results, as they were:
3.3 times more likely to have met or exceeded the company’s productivity goals.
1.6 times more likely to have exceeded company profitability targets.
In this post I will describe DevOps in gereral terms, with some focus on the Business Benefit.
In my next posts I will approach the Operational Model and investigate the technology that can help. Not only tools for Continuous Integration and Continuous Delivery, but also the concept of “infrastructure as code” that allows a flexible and agile use of the infrastructure resources in the same cycle as the software for the applications.

DevOps is a software development method that stresses communication, collaboration (information sharing and web service usage), integration, automation and measurement between software developers and Information Technology (IT) professionals. DevOps is a response to the interdependence of software development and IT operations. It aims to help an organization rapidly produce software products and services and to improve operations performance - quality assurance.
The specific goals of a DevOps approach span the entire delivery pipeline, they include improved deployment frequency, which can lead to faster time to market, lower failure rate of new releases, shortened lead time between fixes, and faster mean time to recovery in the event of a new release crashing or otherwise disabling the current system. Simple processes become increasingly programmable and dynamic, using a DevOps approach, which aims to maximize the predictability, efficiency, security, and maintainability of operational processes. Very often, automation supports this objective.
Development methodologies (such as agile software development) that are adopted in a traditional organization with separate departments for Development, IT Operations and QA, development and deployment activities, previously do not have deep cross-departmental integration with IT support or QA. DevOps promotes a set of processes and methods for thinking about communication and collaboration between departments.
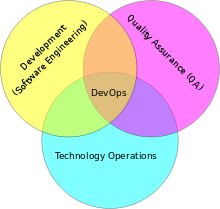
The adoption of DevOps is being driven by factors such as:
- Use of agile and other development processes and methodologies
- Demand for an increased rate of production releases from application and business unit stakeholders
- Wide availability of virtualized and cloud infrastructure from internal and external providers
- Increased usage of data center automation and configuration management tools
Use Cases
Automating the release of a complete system can provide advantages in the following situations (a partial list - if you have more reference, please add a comment to this post):- daily builds in the development environment
- move the system to the integration environment and to QA
- regression testing after a patch
- move a system from testing to production
- deploy a copy of the system for a new tenant
- copy a system to Disaster Recovery
Adoption in the world
DevOps is ramping in the US, it seems to be a little late in Europe - as many innovations in the IT.
Companies that benefit already from the introduction of this methodology are:
Google, Amazon, Netflix, Facebook, Twitter, Pinterest, Bank of America, Cisco and more...
Industry headlines tell us every day that companies rise and fall on moments of infectious delight and irritated disappointment. It's not enough to have a great idea and execute on it once. You have to execute, get feedback, refine, and execute again - and again and again. To keep competitors from grabbing a piece of your market, you need to cycle with ever-increasing speed and agility.
Multiple, independently conducted research studies show that, not only are enterprises already adopting DevOps, they are achieving substantial outcomes.
One such study, conducted by independent research organization IDG, shows that enterprises (measured by having more than $500 million in revenues) are adopting DevOps at an even faster rate than smaller businesses. Another study, conducted by independent research firm Vanson Bourne, found that large enterprises are not only adopting DevOps, but more than 90% have seen or expect to see significant benefits, with quantifiable improvements in delivery speed, development and operations costs, defect detection, ability to innovate, and many more, ranging from 17% to 23%. Then there is additional research from InformationWeek, which also shows high rates of adoption and benefits for large enterprises (measured by having 5,000 or more employees).
One such study, conducted by independent research organization IDG, shows that enterprises (measured by having more than $500 million in revenues) are adopting DevOps at an even faster rate than smaller businesses. Another study, conducted by independent research firm Vanson Bourne, found that large enterprises are not only adopting DevOps, but more than 90% have seen or expect to see significant benefits, with quantifiable improvements in delivery speed, development and operations costs, defect detection, ability to innovate, and many more, ranging from 17% to 23%. Then there is additional research from InformationWeek, which also shows high rates of adoption and benefits for large enterprises (measured by having 5,000 or more employees).
In next post, I’ll try to define a operational model:
what teams are involved
what processes do you need
what information do you need
what roles do you need
what skills do you need
Link to next post: DevOps - Operational Model.
Sources:
1 - https://puppetlabs.com/blog/why-every-cfo-should-advocate-devops (Bill Koefoed, the author, is the chief financial officer of Puppet Labs.)
6 - TDD/CI - Test Driven Development/Continuous Integration - Colin McNamara

















